Spark大数据技术与应用 数据处理技术的核心开发实践
随着数据量的爆炸式增长,传统的数据处理框架已难以满足海量、高速、多样数据的分析需求。Apache Spark作为一种开源、通用、高效的大数据处理引擎,凭借其卓越的内存计算能力、丰富的API支持及灵活的部署方式,已成为现代大数据技术栈中的核心组件。本文将探讨Spark在数据处理技术开发中的关键应用与实践。
一、Spark技术架构与核心优势
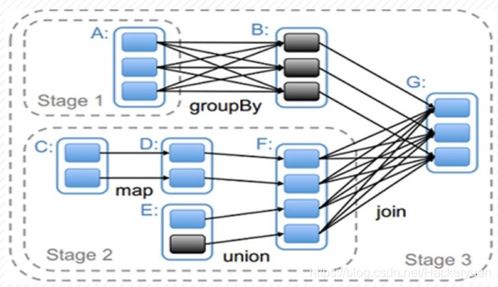
Spark的核心架构基于弹性分布式数据集(RDD)和统一的数据抽象层,提供了批处理、流处理、机器学习、图计算等多种计算模型。其核心优势主要体现在:
- 内存计算:通过将中间数据存储在内存中,显著减少磁盘I/O,使迭代计算和交互式查询性能提升数十倍。
- 统一开发栈:Spark SQL、Spark Streaming、MLlib(机器学习)、GraphX(图计算)等组件共享同一API和运行时环境,简化了开发流程。
- 容错性高:基于RDD的血缘(Lineage)机制,无需数据复制即可实现高效的容错恢复。
- 易用性与兼容性:支持Java、Scala、Python和R语言,并能与Hadoop HDFS、Hive、Kafka等大数据生态无缝集成。
二、数据处理技术开发中的关键应用
1. 批处理与ETL开发
Spark Core和Spark SQL为大规模数据批处理提供了高效解决方案。开发者可通过DataFrame和Dataset API进行结构化数据的ETL(提取、转换、加载)操作,例如数据清洗、格式转换、聚合统计等。代码示例如下(使用PySpark):`python
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ETLExample").getOrCreate()
df = spark.read.csv("hdfs://path/to/data.csv", header=True)
dfclean = df.filter(df["age"] > 18).groupBy("city").agg({"income": "avg"})
dfclean.write.parquet("hdfs://path/to/output")`
2. 流处理与实时计算
Spark Streaming和Structured Streaming支持高吞吐、低延迟的实时数据处理。适用于日志分析、实时监控、在线推荐等场景。开发者可通过微批(Micro-batch)或连续处理模式处理Kafka、Flume等数据源的数据流。
3. 机器学习与数据挖掘
MLlib提供了丰富的机器学习算法(如分类、回归、聚类)和特征工程工具。结合Spark的分布式计算能力,可在海量数据上快速训练模型,支持从数据预处理到模型部署的全流程开发。
4. 图计算与复杂分析
GraphX提供了图并行计算API,适用于社交网络分析、路径规划、风险传播模拟等需要处理复杂关联关系的场景。
三、技术开发最佳实践
- 性能优化:合理设置分区数、利用广播变量减少数据传输、通过缓存(cache/persist)复用中间结果、选择高效的序列化格式(如Kryo)。
- 资源管理:根据集群配置动态调整Executor数量、内存分配及并行度,避免资源浪费或OOM(内存溢出)错误。
- 代码可维护性:采用模块化设计,结合单元测试(如使用Spark Testing Base)确保逻辑正确性,并利用日志监控作业运行状态。
- 生态整合:结合Delta Lake实现ACID事务支持,或通过Apache Airflow调度Spark作业,构建端到端的数据管道。
四、未来趋势与挑战
随着云原生和AI驱动的数据分析需求增长,Spark正持续演进:
- Spark on Kubernetes:提升容器化部署的弹性与资源利用率。
- 与AI框架融合:加强与TensorFlow、PyTorch的集成,支持深度学习任务。
- 实时性深化:Structured Streaming持续优化,向更低延迟的事件时间处理发展。
开发中仍需应对数据倾斜调优、小文件处理、多租户安全等挑战。
###
Spark以其强大的生态和持续创新,已成为大数据处理技术开发的事实标准。开发者需深入理解其内核原理,并结合业务场景灵活运用,才能充分发挥其潜力,构建高效、可靠的数据处理系统。从批处理到实时分析,从机器学习到图计算,Spark正推动着数据驱动决策的边界不断扩展。
如若转载,请注明出处:http://www.yingling8888.com/product/44.html
更新时间:2026-04-17 07:48:03