TiDB云原生数据库 技术架构与数据处理开发实践
在当今数据驱动的时代,企业对于数据处理技术的需求正朝着高并发、高可用、强一致性与弹性扩展的方向飞速发展。传统的单机数据库或主从架构在面对海量数据与复杂业务场景时,往往力不从心。TiDB,作为一款开源的分布式NewSQL数据库,凭借其云原生设计理念和与MySQL高度兼容的特性,成为了构建现代数据平台的明星选择。本文将从其核心架构出发,探讨在数据处理技术开发中的实践应用。
一、TiDB核心技术架构解析
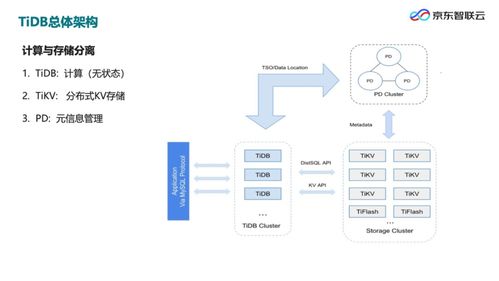
TiDB的整体架构清晰地将计算与存储分离,主要由三个核心组件构成:
- TiDB Server(计算层):
- 角色:无状态的SQL层,负责接收客户端连接、解析SQL、优化查询计划、生成分布式执行计划。
- 特点:完全兼容MySQL协议和语法,应用可近乎无缝迁移。其无状态设计便于水平扩展,通过负载均衡器即可轻松应对流量高峰。
- TiKV Server(存储层):
- 角色:分布式、支持事务的键值存储引擎,是数据持久化的核心。
- 核心技术:
- Raft共识协议:确保数据在多副本间强一致、高可用。每个数据Region(默认96MB~144MB)都是一个Raft Group。
- Multi-Raft:将整个数据集划分为众多Region,并发运行大量Raft组,极大提升了并行处理能力和吞吐量。
- 分布式事务:采用两阶段提交(2PC)与乐观锁模型,并内置了时间戳授时器(PD),提供快照隔离(SI)和读已提交(RC)隔离级别。
- Placement Driver (PD)(调度与元管理层):
- 角色:集群的“大脑”,负责全局元数据管理、TiKV节点与数据Region的调度、以及全局时间戳的分配。
- 功能:通过持续监控集群状态,自动进行负载均衡、故障恢复(如Leader重选、副本补全)、热点Region调度等,确保集群始终处于最优工作状态。
TiFlash作为列式存储引擎,通过Raft Learner协议异步从TiKV复制数据,与行存引擎TiKV形成HTAP(混合事务/分析处理)架构,使得一套系统既能高效处理在线事务,也能进行实时数据分析,避免了复杂的ETL过程。
二、在数据处理技术开发中的核心实践
基于上述架构,开发者在构建数据处理系统时可以获得诸多优势与实践启发:
1. 弹性伸缩,应对业务增长
- 实践:在业务快速增长或存在明显波峰波谷(如电商大促)的场景下,可根据需求动态增删TiDB Server(计算节点)和TiKV Server(存储节点)。PD会自动将数据和负载重新调度到新节点上,整个过程对应用透明。这为容量规划与成本控制提供了极大的灵活性。
2. 高可用与容灾设计
- 实践:TiDB默认采用多副本(通常为3副本)存储。任何单个节点、甚至整个可用区(AZ)的故障,都不会导致数据丢失或服务长时间中断。Raft协议能快速选举出新Leader,PD会调度新副本以维持复制因子。开发者可以基于此,轻松构建同城多活或异地灾备方案,将容灾能力从数据库层面提升到架构层面。
3. 简化复杂事务处理
- 实践:对于需要跨多个分片(或传统分库分表中间件中多个表)的复杂事务,TiDB提供了原生的分布式事务支持。开发者无需再在应用层小心翼翼地处理分布式事务的补偿逻辑(如Saga模式),可以像使用单机MySQL一样使用
BEGIN、COMMIT,极大降低了业务开发的复杂度与出错概率。
4. 实现实时HTAP分析
- 实践:在数据仓库/OLAP场景中,传统链路是T+1地将OLTP数据同步到分析型数据库。借助TiFlash,开发者可以:
- 为需要分析的TiDB表创建列存副本(ALTER TABLE ... SET TIFLASH REPLICA ...)。
- 在SQL中通过优化器提示(如/+ read_from_storage(tiflash[table_name]) /)或由TiDB智能选择,让分析查询直接路由到TiFlash执行,获得极致的列存分析性能。
- 这意味着订单分析、实时报表、风控查询等业务可以运行在最新的数据上,实现真正的实时决策。
5. 与大数据生态无缝集成
- 实践:TiDB提供了丰富的数据导入导出工具(如Dumpling, TiDB Lightning)以及与Apache Spark的直接集成(TiSpark)。这使得它能够:
- 作为海量历史数据的统一存储和查询入口。
- 方便地将数据批量同步到Hadoop或数据湖中进行深度挖掘。
- 利用Spark的强大算力,在TiKV/TiFlash上执行更复杂的分布式机器学习或ETL任务。
三、开发注意事项与最佳实践
- Schema设计:虽然兼容MySQL,但为发挥分布式优势,表应有明确的主键(最好具有单调递增属性以避免热点),并合理使用聚簇索引。避免超宽表,关注热点Region的分布。
- SQL优化:充分利用TiDB的SQL优化器(如CBO)和执行计划查看功能(
EXPLAIN)。对于复杂查询,合理使用索引和TiFlash列存引擎是关键。 - 监控与运维:善用TiDB Dashboard、Prometheus+Grafana等原生监控工具,密切关注关键指标如QPS、延迟、存储容量、Region健康度等,做到 proactive 运维。
###
TiDB通过其精巧的云原生分布式架构,将数据库的扩展性、可用性与易用性提升到了一个新的高度。对于技术开发者而言,它不仅仅是一个数据库替换选项,更是一种构建现代化、面向未来的数据处理平台的全新范式。将TiDB融入技术栈,能够有效应对数据量激增、业务复杂度提升和实时性要求严苛的挑战,让团队更专注于业务逻辑创新,而非底层数据基础设施的维护。
如若转载,请注明出处:http://www.yingling8888.com/product/69.html
更新时间:2026-02-24 22:57:05